
By Nazanin Delam, Staff Software Engineer
Artificial Intelligence is emerging in most industries today, and the world of finance is not immune.
But what is Artificial Intelligence (or AI)? Technically there is no accurate, predictive and measurable definition, but the concept began with Alan Turing’s seminal paper “Computer Machinery and Intelligence” in 1950, where he proposed a question: “Can machines think?”
To answer that question he suggested a game — The Imitation Game.
The objective of the game was simple — for the machine to become indistinguishable from a human by exhibiting intelligent behavior. Thus began The Turing Test, judging natural language conversations between a human and a machine. (The Turing Test can of course fail, since human behavior and intelligent behaviors are two different things. We as humans have behaviors which are unintelligent and some intelligent behaviors can be inhuman.)
Turing predicted that machines would eventually be able to pass the test. In fact, he estimated that by the year 2000, machines with around 100 MB of storage would be able to fool 30% of human judges in a five-minute test and that people would no longer consider the phrase “thinking machine” contradictory. He further predicted that machine learning would be an important part of building powerful machines, a claim considered plausible by contemporary researchers in artificial intelligence.

We’ve now had multiple breakthroughs in which AI beat human intelligence, including in January 2016 when Google’s DeepMind Alpha Go defeated Lee Sedol, the world’s second-highest ranking player of the ancient Chinese game of Go with its new deep learning approach. Or when Microsoft demonstrated a speech recognition system that is as accurate as professional transcriptionists.
So it turns out Turing’s predictions were not out of reach. At this point we’ve all interacted with some form of AI — Amazon Alexa, smart watches, face recognition applications, or self-driving cars roaming Silicon Valley.
But what about the finance industry? How will AI affect fintech?
AI has the potential to improve the finance industry by bringing in efficiency and learning from present data. (Or to devastate the industry with a blackout… But let’s look on the bright side for the sake of this article.)
Highly complicated and efficient algorithms for the finance industry are already common. Finance inherently holds complex mathematical and statistical statements, but the changing determinant today is the significant amount of data available to analyze with cheaper and faster hardware to parallelize this data analysis. In fact, according to an EFMA 2017 study, leading banks of the world over agree that AI will become the primary way in which they will interact with their customers within the next three years.

In today’s fintech world AI plays a role in so many aspects of the industry, including compliance, robo advice, forecasting, market prediction, pattern recognition of client behavior, risk management, fraud and anomaly detection, and even trading.
What we refer to today as Artificial Intelligence is a group of related technologies including Natural Language Processing, Machine Learning, Expert Systems, Image Processing, Game Theory, Motion Planning, Social Intelligence, and much more.
I’d like to drill down into one key method of Machine Learning for finance, Deep Learning, which can be used to solve two types of AI problems: classification and prediction. Applying deep learning methods to these problems can produce more useful results than standard methods in finance. In particular, deep learning can detect and exploit interactions in the data that are, at least currently, invisible to any existing financial economic theory.
Current Models of Deep Learning Used in Fintech
LSTM Deep Neural Networks
Long short-term memory (LSTM) networks are a state-of-the-art technique for sequence learning. They are less commonly applied to financial time series predictions, yet inherently suitable for this domain.
We experimented with LSTM networks during last year’s MyVest Hackathon to predict out-of-sample directional movements for the constituent stocks of the S&P 500 from 1995 until 2017. With daily returns of 0.46 percent and a Sharpe Ratio of 5.8 prior to transaction costs, we found LSTM networks to outperform memory free classification methods (i.e. a random forest [RAF], a deep neural net [DNN], and a logistic regression classifier [LOG]).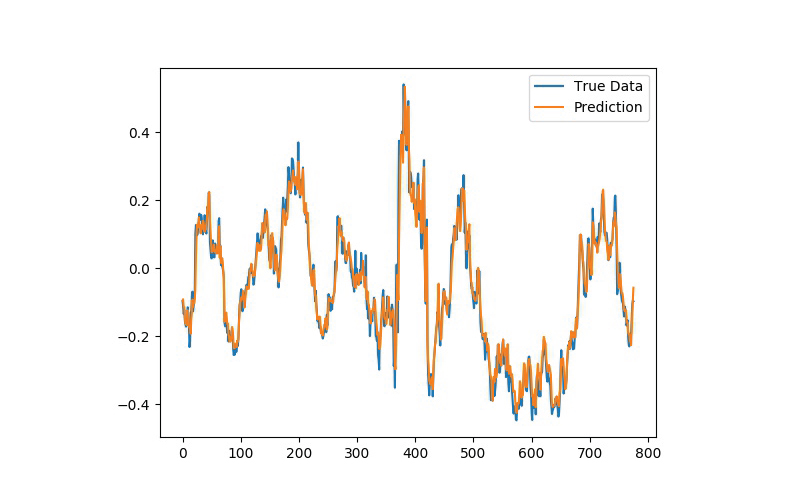
Alpaca is a venture-backed fintech startup that uses LSTM and CNN networks to build Database and AI technologies for financial trading to be able to backtest trades within 5-year range. (If you’re interested learning more about LSTM deep neural networks follow this blog: http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
Genetic Algorithms
Genetic algorithms (GAs) are heuristics problem-solving methods that imitate the process of natural evolution. Unlike artificial neural networks (ANNs), designed to function like the human brain, these algorithms utilize the concepts of natural selection to determine the best solution for a problem. As a result, GAs are commonly used as optimizers that adjust parameters to minimize or maximize some feedback measure, which can then be used independently or in the construction of an ANN.
In the financial markets, genetic algorithms are most commonly used to find the best combination values of parameters in a trading rule, and they can be built into ANN models designed to pick stocks and identify trades. To learn more: http://www.turingfinance.com/using-genetic-programming-to-evolve-security-analysis-decision-trees.
Several studies have demonstrated that these methods can prove effective, including “Genetic Algorithms: Genesis of Stock Evaluation” (2004) by Rama, and “The Applications of Genetic Algorithms in Stock Market Data Mining Optimization” (2004) by Lin, Cao, Wang, Zhang.
Classification and Clustering
Classification is the placing of objects into predefined groups. This type of supervised learning process is also called pattern recognition. Clustering is related to classification. Both techniques place objects into groups or classes. The important difference is that the classes are not predefined in a cluster analysis. Instead, objects are placed into ‘natural’ groups. Therefore, clustering algorithms are unsupervised.
Classification can be effectively used in the risk management, insights, portfolio analysis, and most interestingly social network analysis.

AI at scale
All these methods described above are simply low-level solutions which are the base of scaled frameworks used in fintech companies to apply AI.
Scalability is one of the most challenging problems to overcome before adopting deep learning in any application, that means the deep learning system must be able to provide for a huge demand for computing resources for training large models with massive datasets.
Software
There are many tools and frameworks available for scalable, enterprise deep learning and AI solutions such as TensorFlow, Torch, H2O, MxNET, and DeepLearning4j. All these support multi-GP multi-node highly data parallelism with some checkpoint and recovery solutions. Rather than H2O, all these frameworks developed in C++.
Automated Predictive Modeling is another enterprise level adopted strategy to deal with complex deep learning models at scale. This new cognitive platform introduced by SparkCognition in 2016 which leverages various AI and machine learning algorithm to build custom models and expose those too complex data streams in sophisticated spaces with randomness and stochastic processing such as volume trading. The platform uses a Deep Hashed Artificial Neural Network with two feed forward layers, Spark, Hadoop, and integrated Deep NLP capability.

AI Technology Stack (Image courtesy of Shivon Zilis and James Cham, designed by Heidi Skinner)
Hardware
Multi-GPU setup is another answer to scalability for deep learning applications. Facebook recently published a paper (https://arxiv.org/abs/1706.02677) on how they ran successfully a Resnet-50 layer model on ImageNet dataset with a mini-batch size of 8192 images in an hour using 256 GPU’s. Facebook uses a technique called Distributed Synchronous Stochastic Gradient Descent (SGD) mini batching. In Distributed Synchronous SGD, each GPU runs the same graph on a subset of the mini batch data. Once the GPU completes processing, the weights are transferred to parameter server which aggregates all the gradients from multiple GPU’s and sends back to them.
There are few other methods required, one of which is Linear scaling, a warm-up strategy to allow the model to achieve results on par to the models trained on smaller batches on a single GPU.
Conclusion
AI is spreading throughout our daily lives and has penetrated the broad financial industry. Deep learning has also established itself in newer fintech services, as evidenced by last fall’s Benzinga Fintech Summit, where we saw the introduction of smarter customer insight analytics, portfolio management applications and robo advisory.
Companies that learn from user experience, mine for meaningful data, and apply AI and heuristics to enhance that experience will hold a competitive advantage. The fintech industry is uniquely positioned at the confluence of these three areas, and is ripe for consumers to benefit from these emerging AI solutions.
About Nazanin

Nazanin is part of the team leading UI initiatives at MyVest. She has master degrees in Computer Science and Cognitive Science and she is a certified MIT System Engineer.
Nazanin is dedicated to advancing the role of women in engineering. She volunteers with Hour of Code teaching high school girls how to code and serves as a member of Women Who Code and Women Tech Makers.
She also enjoys working on self-driving cars and image recognition applications, and in her free time she contributes to open source projects, builds funny robots and reads books.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of MyVest, its affiliates, or its employees.




